Le mode de confidentialité avancé des vidéos YouTube embarquées n’est pas suffisant pour être en pleine conformité par rapport au RGPD mais il n’active les cookies qu’en cas d’interaction avec la vidéo. Petite vidéo pour visualiser comment récupérer le code dans YouTube (et l’occasion d’un petit test SEO en passant – résultats coming soon 😉 ).
Catégorie : Référencement naturel
Les moteurs de recherche, on s’en sert tout le temps, on ne se pose plus beaucoup de questions.
Et comment fonctionnent-ils ? C’est compliqué mais il n’est pas nécessaire d’être un génie pour saisir quelques grandes lignes et améliorer son référencement.
Ici, quelques bribes de réponse. Bonne lecture !
-
Des accents dans les URL de sitemap
Concrètement, peut-on utiliser des caractères accentués dans un sitemap ? « Demande à Google ! »… Bon réflexe, mais sa documentation ne traite pas tous les cas de figure, et c’est peut-être pour ça que vous êtes en train de lire ces lignes.
Alors trêve de suspense : oui, si on gère correctement l’encodage. La preuve en image, résultat d’un petit test :
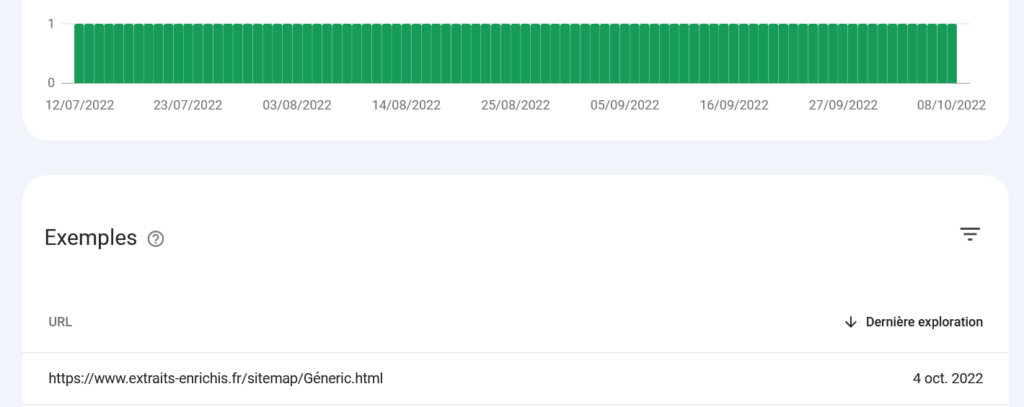
C’est simple, c’est vert, c’est magnifique ! Enfin une tâche d’indexation sans problème Pour remonter à l’origine de ce test, c’est par là : https://www.extraits-enrichis.fr/sitemap/G%C3%A9neric.html
-
Des résultats enrichis Guide / Tuto avec les données structurées HowTo
C’est quoi un résultat enrichi Guide / Tuto ? C’est un résultat de moteur de recherche particulièrement mis en valeur au milieu des autres résultats.
C’est quoi les données structurées HowTo ? C’est tout simplement le moyen d’obtenir ce genre de résultats enrichis.
Mettre en place des données structurées « How To » est une optimisation SEO immanquable pour un tutoriel ou guide pratique en X étapes.Sommaire
- L’affichage des résultats enrichis pour les guides / tutoriels (« en X étapes » ou « pas à pas »)
- Les données structurées HowTo
- HowTo et les moteurs de recherche
- HowTo dans schema.org
- Les données structurées de type HowTo dans schema.org
- Les prérequis pour obtenir un résultat enrichi de Guide
- Sujets / autres résultats enrichis en relation
L’affichage des résultats enrichis pour les guides / tutoriels (« en X étapes » ou « pas à pas »)
Le résultat enrichi de « guide » (tutoriel pas à pas) a différentes formes en fonction du contenu dont vous disposez : texte simple, photos ou vidéo. Ci-dessous, la cas où une image est associée à chaque étape du guide « Comment régler les freins d’un vélo » :
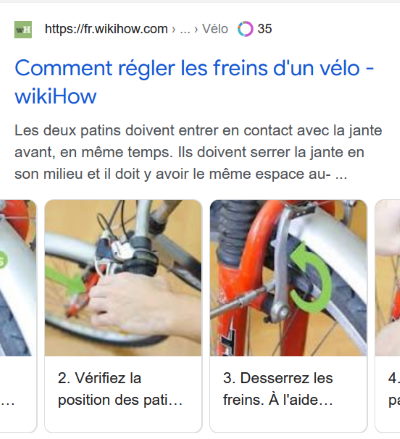
Avec son carrousel, un résultat de tutoriel « simple » avec des données structurées est quand même bien plus visible qu’un résultat classique (JDCJDR) Difficile de faire mieux pour l’utilisateur qui obtiendra un maximum d’infos dans la page .. de Google. C’est plus compliqué pour les éditeurs de sites, dont le contenu est « proposé » gracieusement dans Google et qui ne voient plus une partie des visiteurs (les visiteurs qui trouvent dans la page du moteur tout ce qu’ils cherchent).
Les données structurées HowTo
HowTo et les moteurs de recherche
Google et Bing utilisent les informations suivantes pour les résultats enrichis Guide :
- Le nom du tuto
- Chaque étape, détaillée, avec ou sans image ou vidéo, regroupée ou pas avec d’autres étapes dans des sections de guide
- Le coût estimé des fournitures
- L’image finale
- Le matériel utilisé
- Les outils utilisés
- Le temps nécessaire
HowTo dans schema.org
Dans schema.org, HowTo est rattaché à l’entité CreativeWork (après Thing, of course! ) :
Thing > CreativeWork > HowTo
On peut donc piocher dans les propriétés schema.org de type HowTo et CreativeWork pour personnaliser ses données structurées.
Les prérequis pour obtenir un résultat enrichi de Guide
Obligations, interdictions, contraintes
Pour avoir un résultat enrichi de Guide dans Google, les seules propriétés obligatoires sont le nom et les étapes : les étapes sont elles-mêmes composées d’autres propriétés (
HowToStepouHowToSection). Il y a bien d’autres informations que l’on peut fournir : des images ou une vidéo (pour illustrer chaque étape), la durée et le coût de réalisation, le matériel nécessaire, …Il y aussi quelques interdits et obligations quant au contenu … dans les données structurées HowTo, pas de pub, de « contenu obscène, grossier ou sexuellement explicite, des images violentes, s’il fait la promotion d’activités dangereuses ou illégales, ou encore s’il contient des propos haineux ou offensants ».
Tout le contenu doit être accessible dans la page, il faut donner des instructions suffisamment complètes… et le guide ne doit
- ni être une recette de cuisine (voir les données structurées de type Recipe, pour des résultats avec étoiles de notation, photo et temps de préparation)
- ni être un conseil d’ordre général (comment bien vieillir à partir de 30 ans en 5 points, 6 étapes pour être heureux sur Twitter, progresser en tout point en 7 étapes … c’est pas bon).
Faites n’importe quoi si vous le voulez, mais il y a un guide disponible !
Code JSON-LD pour les données structurées HowTo, la preuve par l’exemple
{ "@context": "https://schema.org", "@type": "HowTo", "name": "Mettre en place des données structurées HowTo pour obtenir des résultats enrichis de type Guide", "image": { "@type": "ImageObject", "url": "https://www.extraits-enrichis.fr/wp-content/uploads/2022/10/howto-step-1-ee.gif", "height": "600", "width": "640" }, "estimatedCost": { "@type": "MonetaryAmount", "currency": "EUR", "value": "0" }, "supply": [ { "@type": "HowToSupply", "name": "Site Web" }, { "@type": "HowToSupply", "name": "Temps" }, { "@type": "HowToSupply", "name": "Fun" }, { "@type": "HowToSupply", "name": "Générosité" } ], "tool": [ { "@type": "HowToTool", "name": "Ordinateur" }, { "@type": "HowToTool", "name": "Connexion internet" },{ "@type": "HowToTool", "name": "Article Les données structurées de guide (How To) du site Extraits enrichis" } ], "step": [ { "@type": "HowToStep", "url": "https://www.extraits-enrichis.fr/tutoriel-donnees-structurees-how-to#preparer-contenus-howto", "name": "Avoir un contenu adapté", "itemListElement": [{ "@type": "HowToDirection", "text": "Vérifier que le contenu soit suffisamment utile et concret" }, { "@type": "HowToDirection", "text": "Vérifier aussi que le contenu n'enfreint pas les consignes de Google (pas de pub, de contenu obscène, violent, ..." }, { "@type": "HowToDirection", "text": "Vérifier enfin que le contenu soit bien décomposé en étapes, et que toutes les étapes sont bien présentes dans la page." }, { "@type": "HowToTip", "text": "Les résultats enrichis illustrés avec des images, voire une vidéo, sont mieux visibles que ceux qui n'en ont pas." }], "image": { "@type": "ImageObject", "url": "https://www.extraits-enrichis.fr/wp-content/uploads/2022/10/howto-step-1-ee.gif", "height": "600", "width": "640" } }, { "@type": "HowToStep", "name": "Intégrer les données structurées", "url": "https://www.extraits-enrichis.fr/tutoriel-donnees-structurees-how-to#integrer-donnees-structurees-howto", "itemListElement": [{ "@type": "HowToTip", "text": "Si vous utilisez un CMS, il devrait y avoir une extension, plugin ou module qui devrait vous faciliter la tâche." }, { "@type": "HowToDirection", "text": "Renseignez obligatoirement le nom du tutoriel ou guide pas à pas, et chaque étape." }, { "@type": "HowToDirection", "text": "Chaque étape doit être renseigné dans une liste HowToStep contenant des items HowToDirection ou HowToTip. Les HowToStep peuvent être regroupés dans des HowToSection. Les seuls champs obligatoires sont les listes et le texte des items." }, { "@type": "HowToDirection", "text": "Il est préfarable de vérifier le code de vos données structurées, par exemple avec le test des résultats enrichis de Google : une coquille est si vite arrivée." }], "image": { "@type": "ImageObject", "url": "https://www.extraits-enrichis.fr/wp-content/uploads/2022/10/howto-step-2-ee.gif", "height": "600", "width": "640" } }, { "@type": "HowToStep", "name": "Profiter des résultats enrichis HowTo des moteurs de recherche ", "url": "https://www.extraits-enrichis.fr/tutoriel-donnees-structurees-how-to#affichage-resultats-enrichis-howto", "itemListElement": [{ "@type": "HowToDirection", "text": "Patientez suffisamment, le temps que vos données structurées aient été découvertes et analysées par les moteurs de recherche." }, { "@type": "HowToDirection", "text": "Impressionnez vos relations en leur envoyant des captures d'écran de Google avec le résultat enrichi HowTo de votre précieux guide." }], "image": { "@type": "ImageObject", "url": "https://www.extraits-enrichis.fr/wp-content/uploads/2022/10/howto-step-3-ee.gif", "height": "600", "width": "640" } } ], "totalTime": "PT1H" }Spécifications officielles
- Les consignes des propriétés prises en compte par Google sont heureusement accessibles chez Google
https://developers.google.com/search/docs/appearance/structured-data/how-to - Pour découvrir l’ensemble des données structurées de type HowTo :
https://schema.org/HowTo - Petit rappel, s’il s’agit d’une recette de cuisine, ce sont les données structurées Recipe qu’il faut mettre en place.
Sujets / autres résultats enrichis en relation
- Les données structurées de type Recipe, qui sont en fait un type spécifique de HowTo dédié aux recettes de cuisine dans les résultats des moteurs de recherche
> Recette de cuisine et Google : les résultats enrichis - Les données structurées de type LocalBusiness, pour transmettre des informations en lien avec une fiche d’établissement Google Maps, My Business, Local, Place, Address …
> Établissement local et données structurées - Avec les données structurées de type Logo, vous pouvez indiquer à Google quel est le logo de votre organisation.
> Votre logo dans les résultats de Google et sa fiche info - Qu’est-ce qu’un fil d’Ariane, HTML ou dans Google ? A quoi ça sert ? Comment en ajouter facilement ?
> Fil d’Ariane et résultats enrichis - Un extrait enrichi est un résultat un peu particulier dans les moteurs de recherche. Petite explication pour les curieux 💡
> Google et les extraits de résultats enrichis
-
Les recettes de cuisine affichées dans Google sous forme de résultats enrichis
Sommaire
- De quoi parle-t-on ?
- Les données structurées de type Recipe (Recette)
- Sujets / autres résultats enrichis en relation
De quoi parle-t-on ?
Vous avez remarqué dans les moteurs de recherche ces résultats de recettes de cuisine : vignette photo, étoiles, … Il s’agit de résultats enrichis (qui existent aussi pour d’autres sujets : produits, actualités, livres, … la liste est longue).
Et si c’était le moment d’apprendre à utiliser des données structurées de type Recipe, qui permettent justement d’afficher, dans les résultats des moteurs de recherche, des recettes de cuisine avec étoiles de notation, photo et temps de préparation ?
L’affichage des résultats enrichis de recettes de cuisine
Un tour express des affichages de résultats enrichis pour les recettes de cuisine
Le « simple » résultat enrichi parmi les autres résultats naturels
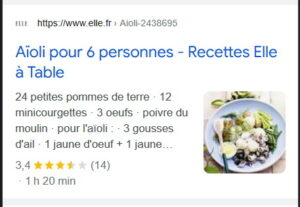
Un résultat de recette enrichi « simple », qui sent bon par où ça passe 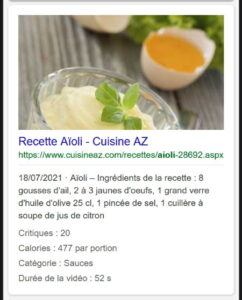
Microsoft Bing connait aussi les plus grandes recettes internationales, et les données structurées Recipe, avec quelques infos supplémentaires affichées (ex : calories, catégorie, durée de la vidéo) Le bloc spécifique de Recettes
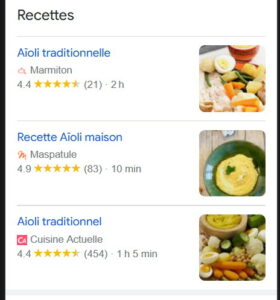
Un bloc Recettes, pour 3 fois plus de saveurs Le carrousel de recettes d’un site (qui nécessite un second type de données structurées, « ItemList »)
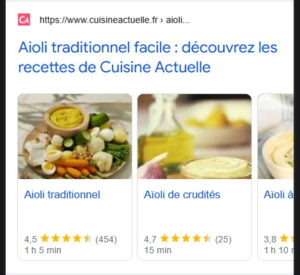
Le grand défi : tester les différentes recettes proposées par un site pour choisir la meilleure, grâce au carrousel de recettes Les contextes spécifiques à l’assistant Google
Plus précisément l’utilisation d’enceintes et d’écrans connectés (qui nécessite des propriétés de données structurées supplémentaires)
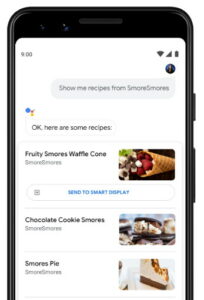
Google Assistant et la proposition d’envoyer la « recette guidée » sur un écran connecté Les informations à ajouter pour une recette : de nombreuses possibilités
Selon schema.org, les possibilités sont nombreuses, et Google et Bing prennent en charge un nombre conséquent de propriétés schema.org pour assaisonner leurs résultats de recherche de recettes :
- Le nom de la recette
- Une photo du plat, sa description, des mots-clés associés
- Le type de plat et le type de cuisine
- La liste des ingrédients et la quantité obtenue
- Les étapes de réalisation de la recette pas à pas
- Une vidéo de la recette
- Une notation liée à des avis utilisateurs
- Le créateur de la recette
- Les durées de préparation, de cuisson, et totale
- La date de publication de la recette
- Les calories par portion
Il existe aussi
- les carrousels de recette : une liste de recette associées, publiées sur un site, affichée sous le résultat
- les recettes guidées : une format plus détaillé qui permet d’intégrer les réponses des enceintes et écrans connectés Google Home
Ces 2 résultats enrichis associés aux recette de cuisine ne sont pas encore détaillées ici, mais vous pouvez trouver plus d’informations dans les spécifications.
Les données structurées de type Recipe (Recette)
La situation de Recipe dans la hiérarchie des propriétés schema.org
Le type Recipe est rattaché à deux entités (après Thing, bien entendu) : CreativeWork et HowTo.
Thing > CreativeWork > HowTo > Recipe
On peut donc enrichir les données structurées de type Recipe avec des propriétés de ces 2 types d’entités, tant que cela reste de bon goût.
Les prérequis
Pour Google, les seules propriétés obligatoires à ajouter sont le nom et l’image de la recette : dans les faits, on voudra voir apparaître la notation avec ses étoiles colorées (notation pouvant être issue d’un système de vote ou d’évaluations individuelles), les temps de préparation et de cuisson, les instructions, …
Rien n’interdit d’aller au-delà des propriétés que Google prend en charge en piochant dans https://schema.org/Recipe : suitableForDiet, estimatedCost, tool, award, comment, … la liste est longue.
Code JSON-LD pour les données structurées Recipe, exemple d’une célèbre recette de sauce dénaturée
{ "@context": "https://schema.org/", "@type": "Recipe", "name": "Aïoli mayonnaise", "image": [ "https://www.extraits-enrichis.fr/wp-content/uploads/2022/04/rich-result-aioli-illustration-1x1-1.jpg", "https://www.extraits-enrichis.fr/wp-content/uploads/2022/04/rich-result-aioli-illustration-4x3-1.jpg", "https://www.extraits-enrichis.fr/wp-content/uploads/2022/04/rich-result-aioli-illustration-16x9-1.jpg" ], "author": { "@type": "Person", "name": "J. Michotey" }, "datePublished": "2022-04-20", "description": "La sauce idéale pour limiter les effets salutaires d'un poisson et de légumes cuits à la vapeur !", "recipeCuisine": "Pseudo-Marseillaise", "prepTime": "PT5M", "cookTime": "PT0M", "totalTime": "PT5M", "keywords": "aïoli, ail, mayonnaise, mayo, été", "recipeYield": "1 serving", "recipeCategory": "Sauce", "nutrition": { "@type": "NutritionInformation", "calories": "700 calories" }, "review": { "@type": "Review", "reviewRating": { "@type": "Rating", "ratingValue": "5" }, "author": { "@type": "Person", "name": "Maman" }, "reviewBody": "Vraiment l'aïoli le meilleur que j'ai gouté, même si ce n'est pas le traditionnel, je me suis régalée." }, "recipeIngredient": [ "1 jaune d'oeuf", "un peu de moutarde (facultatif)", "de l'huile", "une pincée de sel", "une pincée de poivre (facultatif)", "de l'ail" ], "recipeInstructions": [ { "@type": "HowToStep", "text": "Mélanger le jaune d'oeuf et une pointe de moutarde dans un bol de façon régulière à l'aide d'un fouet." }, { "@type": "HowToStep", "text": "Ajouter progressivement un très léger filet d'huile en continuant de mélanger de façon régulière. La mayonnaise doit commencer à prendre assez rapidement, elle monte petit à petit. Interrompre le filet d'huile en continuant à tourner pour éviter de noyer l'émulsion. Continuer à tourner pendant un moment après avoir obtenu la quantité souhaitée pour obtenir une mayonnaise bien ferme." }, { "@type": "HowToStep", "text": "Raper ou écraser de l'ail et assaisonner selon votre goût, et mélanger une dernière fois." } ] }Spécifications officielles
- Pour retrouver la liste officielle des propriétés prises en compte par Google et ses préconisations détaillées, c’est bien entendu chez Google
https://developers.google.com/search/docs/appearance/structured-data/recipe - Pour découvrir l’ensemble des données structurées de type Recipe :
https://schema.org/Recipe
Et les autres données structurées associées (recettes guidées et carrousel de recettes notamment) :
https://schema.org/HowToSection
https://schema.org/HowToStep
https://schema.org/HowToDirection
https://schema.org/HowToTip
https://schema.org/ItemList
Sujets / autres résultats enrichis en relation
- Un résultat enrichi Guide / Tuto avec des données structurées HowTo pour augmenter la visibilité de votre contenu « tuto en X étapes » dans les résultats des moteurs
> Des résultats enrichis Guide / Tuto avec les données structurées HowTo - Les données structurées de type LocalBusiness, pour transmettre des informations en lien avec une fiche d’établissement Google Maps, My Business, Local, Place, Address …
> Établissement local et données structurées - Avec les données structurées de type Logo, vous pouvez indiquer à Google quel est le logo de votre organisation.
> Votre logo dans les résultats de Google et sa fiche info - Qu’est-ce qu’un fil d’Ariane, HTML ou dans Google ? A quoi ça sert ? Comment en ajouter facilement ?
> Fil d’Ariane et résultats enrichis - Un extrait enrichi est un résultat un peu particulier dans les moteurs de recherche. Petite explication pour les curieux 💡
> Google et les extraits de résultats enrichis
-
Établissement local et données structurées
A quoi ça sert ?
Les données structurées de type LocalBusiness permettent de transmettre aux moteurs de recherche des informations en lien avec la fiche d’établissement Google (Maps, My Business, Local, Place, Address …) : pas inutile pour gérer sa visibilité dès lors qu’on a, en tant que structure locale, une adresse. Il ne faut pas confondre cette fiche d’établissement avec la fiche info dans Google, qui est liée à une entité et pas à un établissement ayant pignon sur rue.
Contextes d’affichage dans les résultats de recherche Google
Attention à ne pas surinterpréter les captures d’écran qui suivent : ce n’est pas en ajoutant des données structurées de type LocalBusiness dans une page qu’une fiche d’établissement apparait dans les résultats Google : ces données structurées permettent simplement de transmettre et confirmer des informations qui apparaissent dans cette fiche : l’adresse, les jours et horaires d’ouverture, le numéro de téléphone, … tout cela est détaillé juste après.
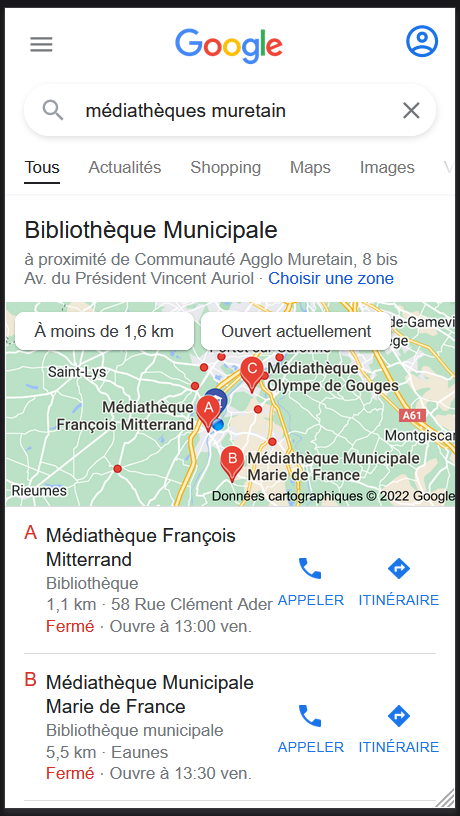
Des résultats localisés, associés à Google (appelés Local Pack Outre-Atlantique) 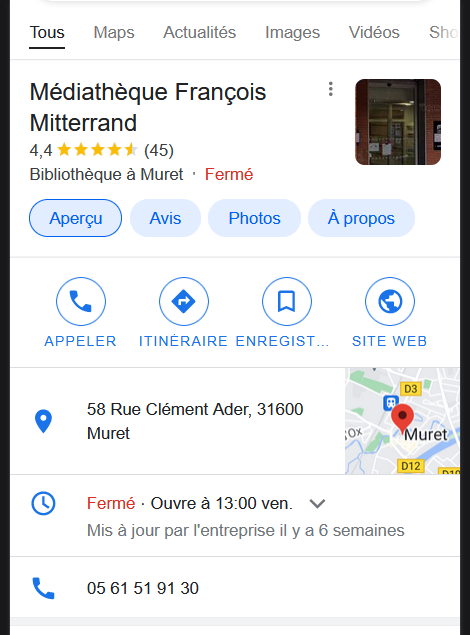
Une fiche d’établissement, avec des photos, un site web, un numéro de téléphone, des horaires d’ouverture, … Quelles sont les données structurées qu’un établissement local peut fournir ?
La liste est susceptible d’évoluer, comme tous les aspects SEO, plus largement tout ce qui est du domaine du numérique, et en règle générale tout ce qui existe. Il y a toutefois un certain nombre d’informations qui sont prises en compte par Google pour le type LocalBusiness de schema.org :
- L’adresse de l’établissement
- Son nom
- Son numéro de téléphone
- Les services proposés
- Sa note moyenne d’évaluation basée sur des avis utilisateurs
- Des avis spécifiques et détaillés
- Ses coordonnées géographiques
- Ses jours et horaires d’ouverture
- Ses dates de fermeture saisonnière
- Sa gamme de prix
- Spécifiquement pour les restaurants, la carte du menu et le type de cuisine proposée
Les spécifications de schema.org ont une palette bien plus large.
Les données structurées d’Établissement local
Situation dans la hiérarchie des propriétés schema.org
Le type LocalBusiness est rattaché à deux entités (après Thing, bien entendu, qui est le point de départ) : Organization et Place.
Thing > Organization > LocalBusiness
Thing > Place > LocalBusinessOn peut donc intégrer des propriétés de ces 2 types d’entités au sein des propriétés du type LocalBusiness.
On peut aussi choisir un type d’entité plus spécifique : AnimalShelter, DryCleaningOrLaundry, EntertainmentBusiness, FoodEstablishment, Library, SportsActivityLocation, et bien d’autres consultables sur schema.org.
Les prérequis
Pour Google, les seules propriétés obligatoires à ajouter sont le nom et l’adresse de l’établissement : ce n’est donc pas très contraignant.
Code d’exemple JSON-LD données structurées LocalBusiness (Organization > LocalBusiness > Library)
{ "@context": "https://schema.org", "@type": "Library", "image": [ "https://mediatheque.mairie-muret.fr/Default/basicimagedownload.ashx?itemGuid=F19938E2-5021-4DB0-A024-83EA6AE3B130" ], "name": "Médiathèque François Mitterrand", "address": { "@type": "PostalAddress", "streetAddress": "58, rue Clément Ader", "addressLocality": "Muret", "addressRegion": "Occitanie", "postalCode": "31600", "addressCountry": "FR" }, "review": { "@type": "Review", "reviewRating": { "@type": "Rating", "ratingValue": "5", "bestRating": "5" }, "author": { "@type": "Person", "name": "Jean Michotey" } }, "url": "https://mediatheque.mairie-muret.fr", "priceRange": "gratuit pour les habitants de l'agglo", "telephone": "+33561519130", "openingHoursSpecification": [ { "@type": "OpeningHoursSpecification", "dayOfWeek": [ "Tuesday", "Thursday", "Friday" ], "opens": "13:00", "closes": "18:00" }, { "@type": "OpeningHoursSpecification", "dayOfWeek": [ "Wednesday" ], "opens": "10:30", "closes": "19:30" }, { "@type": "OpeningHoursSpecification", "dayOfWeek": "Saturday", "opens": "09:30", "closes": "17:00" } ] }Spécifications officielles
- Pour trouver la liste et les préconisations détaillées de Google , c’est bien entendu chez Google
https://developers.google.com/search/docs/advanced/structured-data/local-business?hl=fr - Pour découvrir l’ensemble des données structurées de type LocalBusiness
https://schema.org/LocalBusiness,
https://schema.org/Library,
https://schema.org/EmergencyService,
etc.
Il y a en effet de nombreux « types » de LocalBusiness, du générique LocalBusiness au plus spécifique DryCleaningOrLaundry.
Fiche d’établissement local sur Google : validation et administration
Gérer la fiche d’un établissement n’est pas quelque chose de très compliqué : le plus contraignant est de valider la propriété de la fiche, autrement dit de prouver à Google que vous êtes bien habilité à gérer ces informations. Il existe plusieurs méthodes pour valider une fiche, la plus classique étant le courrier envoyé à l’adresse de l’établissement et contenant un code.
Une fois que l’accès à l’administration de la fiche est débloqué, il est très facile d’y ajouter des photos, des informations, des liens, des messages, …
Sujets / autres résultats enrichis en relation
- Un résultat enrichi Guide / Tuto avec des données structurées HowTo pour augmenter la visibilité de votre contenu « tuto en X étapes » dans les résultats des moteurs
> Des résultats enrichis Guide / Tuto avec les données structurées HowTo - Des données structurées de type Recipe pour faire saliver sur vos recettes de cuisine dans les résultats des moteurs de recherche
> Recette de cuisine et Google : les résultats enrichis - Avec les données structurées de type Logo, vous pouvez indiquer à Google quel est le logo de votre organisation.
> Votre logo dans les résultats de Google et sa fiche info - Qu’est-ce qu’un fil d’Ariane, HTML ou dans Google ? A quoi ça sert ? Comment en ajouter facilement ?
> Fil d’Ariane et résultats enrichis - Un extrait enrichi est un résultat un peu particulier dans les moteurs de recherche. Petite explication pour les curieux 💡
> Google et les extraits de résultats enrichis
-
Votre logo dans les résultats de Google et sa fiche info
Avec les données structurées de type Logo, vous pouvez indiquer à Google quel est le logo de votre organisation. C’est un type de données structurées répandu, parce que facile à mettre en place, mais il faut avoir une certaine renommée pour bénéficier de l’emplacement où ce logo est affiché par Google : la fiche info (Kownledge Panel en anglais). A ne pas confondre avec les fiches établissement, beaucoup plus courantes et liées à un établissement local.
De quoi s’agit-il ?
Un exemple de logo dans les résultats de Google, dans une fiche info
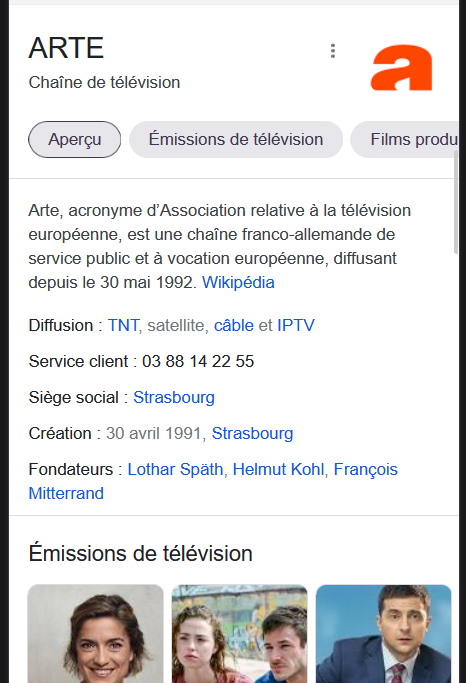
Le logo d’Arte affiché dans la fiche info des résultats Google A quoi ça sert ?
Fournir un logo à Google n’est pas inutile si vous avez une chance d’obtenir une fiche info à court ou moyen terme : le moteur peut se tromper. Des signaux lui ferait peut-être choisir une ancienne version de votre identité visuelle ou pire, une image qui n’a rien à voir avec votre logo. En lui indiquant l’adresse de l’image à utiliser, vous limitez les risques qu’il se trompe.
Si la fiche info vous parait un brin démesurée par rapport à votre notoriété, il faut quand même avoir à l’esprit que transmettre l’information sur votre logo
- est simple,
- ne risque pas de faire de mal à votre référencement,
- participe sans doute aux signaux que Google utilise pour reconnaitre une entité, une marque, une organisation.
En contre-argument, on peut rétorquer que ne pas ajouter ces données structurées économisera un tout petit peu l’énergie.
Les données structurées de Logo
Situation dans la hiérarchie des propriétés schema.org
La propriété Logo peut apparaitre dans les données structurées de type Brand, Organization, Place, Product ou Service.
Le type Organization, présenté ci-dessous, est assez courant, il est simplement rattaché à l’entité Thing mais il a de nombreuses sous-entités dont LocalBusiness, NGO, SportsOrganization ou WorkersUnion.
Thing > Organization
Les prérequis
Les données structurées de Logo ne sont pas très compliquées à déployer : il faut fournir l’adresse d’une image d’au moins 112 pixels de hauteur et de largeur, explorable et indexable par les moteurs de recherche (pistes ici si besoin), visible sur fond blanc, ainsi que l’adresse du site web de l’organisation que le logo représente.
A noter que le logo n’est qu’une propriété des données structurées de type Organization (avec l’accent, s’il vous plait 🙂 )
Code d’exemple JSON-LD données structurées Logo (propriété d’Organization)
{ "@context": "https://schema.org", "@type": "Organization", "url": "http://www.example.com", "logo": "http://www.example.com/images/logo.png" }Spécifications officielles
- Pour trouver la liste et les préconisations détaillées de Google , c’est bien entendu chez Google
https://developers.google.com/search/docs/advanced/structured-data/logo?hl=fr - Pour découvrir les nombreuses propriétés des données structurées de type Organization
https://schema.org/Organization
Sujets / autres résultats enrichis en relation
- Un résultat enrichi Guide / Tuto avec des données structurées HowTo pour augmenter la visibilité de votre contenu « tuto en X étapes » dans les résultats des moteurs
> Des résultats enrichis Guide / Tuto avec les données structurées HowTo - Des données structurées de type Recipe pour faire saliver sur vos recettes de cuisine dans les moteurs de recherche
> Recette de cuisine et Google : les résultats enrichis - Les données structurées de type LocalBusiness, pour transmettre des informations en lien avec une fiche d’établissement Google Maps, My Business, Local, Place, Address …
> Établissement local et données structurées - Qu’est-ce qu’un fil d’Ariane, HTML ou dans Google ? A quoi ça sert ? Comment en ajouter facilement ?
> Fil d’Ariane et résultats enrichis - Un extrait enrichi est un résultat un peu particulier dans les moteurs de recherche. Petite explication pour les curieux 💡
> Google et les extraits de résultats enrichis
-
Fil d’Ariane et résultats enrichis
Savez-vous que les résultats enrichis Fil d’Ariane font partie des premiers résultats enrichis à être apparus dans Google ?
De quoi s’agit-il ?
Un exemple de fil d’Ariane affiché dans une page web
Celui que vous pouvez trouver en haut de cette page :
📌 > Bienvenue ! > Référencement naturel > Résultats enrichis > Résultat enrichi : Fil d’ArianeUn exemple de fil d’Ariane dans les résultats de Google
A quoi ça sert ?
Le fil d’Ariane (aussi appelé chemin de fer, et breadcrumb en anglais) est apparu assez tôt dans les interfaces informatiques et dans les pages web. Il subit fortement des effets de mode, apparaissant et disparaissant au gré des tendances.
Comme vous pouvez le voir, un fil d’Ariane dans une page web permet aux visiteurs d’identifier rapidement la place de la page dans la structure du site.
L’affichage du fil d’Ariane dans les résultats de recherche Google permet au visiteur d’avoir l’information avant même d’avoir cliqué sur le résultat. Le fil d’Ariane aide aussi le moteur à bien comprendre la place de la page dans le site, que ce soit au format HTML ou en données structurées.Dans certains cas, on peut voir plus d’un fil d’Ariane sur une page, il peut s’agir lors
- De différentes « catégorisations » (ou taxonomies) intéressantes pour le visiteur
exemples :
📌 > Bienvenue ! > Référencement naturel > Résultats enrichis > Résultat enrichi : Fil d’Ariane
📌 > Bienvenue ! > Ergonomie web > Fil d’Ariane
📌 > Bienvenue ! > Pages de résultats des moteurs de recherche > Fil d’Ariane - D’un historique de navigation
exemple :
📌 > 1ère page consultée sur le site > 2e page consultée sur le site > Page en cours de consultation
Comment ajouter un fil d’Ariane dans ses pages ?
Le fil d’Ariane version HTML, dans WordPress
Il y a de nombreuses solutions d’intégration de fil d’Ariane dans les sites web, grâce à des thèmes et extensions (pour les CMS) ou avec un peu de développement.
Concernant WordPress, si votre thème ne comporte pas de fil d’Ariane, il est préférable de créer un thème enfant (ce n’est pas une grosse affaire), d’ajouter un peu de code au bon endroit et d’assurer la mise en forme. Rank Math, une extension SEO très efficace, propose (entre autres choses) un code à intégrer et une gestion assez complète du fil d’Ariane.
Le fil d’Ariane version données structurées / résultats enrichis
Situation dans la hiérarchie des propriétés schema.org
Le type Breadcrumb est rattaché à l’entité ItemList, elle-même raccrochée à Intangible puis à Thing. On est donc clairement dans une histoire de listes.
Thing > Intangible > ItemList > BreadcrumbList
Les prérequis
Comme pour tous les résultats enrichis, il est nécessaire d’afficher un vrai fil d’Ariane dans la page, cohérent avec les informations fournies en données structurées : les structures de ces 2 fils d’Ariane doivent être identiques.
La structure
Pour que Google considère votre fil d’Ariane en données structurées comme valide, il faut fournir 3 informations à chaque niveau :
- La position au sein du fil d’Ariane :
1er élément, 2e élément, 3e élément, etc. - Le texte de l’élément :
Accueil, Nom de rubrique, Nom de page, etc. - L’URL de l’élément :
URL de la page d’accueil, de la rubrique, de la page, etc.
A noter que l’URL n’est pas indispensable pour le dernier élément du fil d’Ariane (l’URL de la page sera alors utilisée par Google – attention aux problèmes liés au contenu dupliqué).
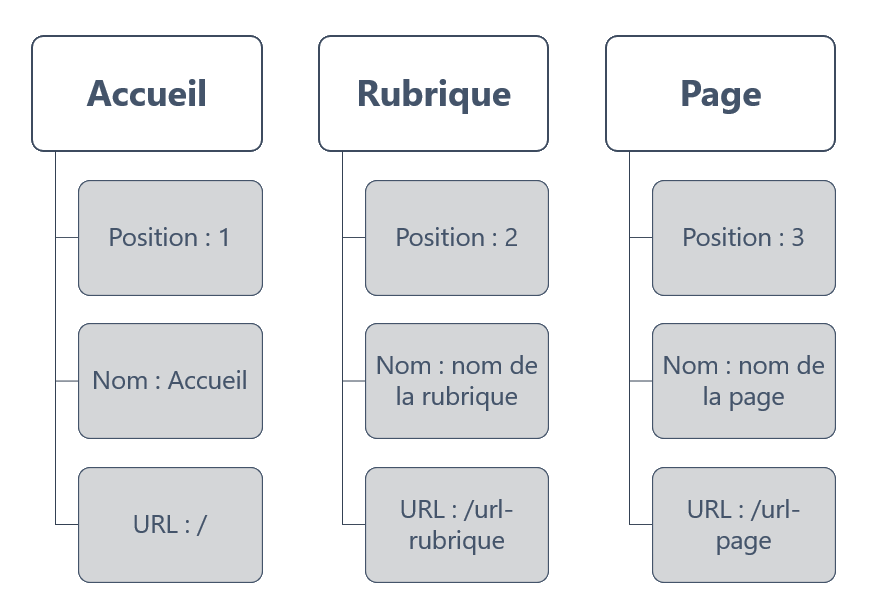
Vue schématique des données structurées à inclure pour un fil d’Ariane Code d’exemple JSON-LD données structurées BreadcrumbList (fil d’Ariane)
{ "@type":"BreadcrumbList", "@id":"https://www.extraits-enrichis.fr/installer-matomo-sur-wp-c-est-rapide-et-facile/#breadcrumb", "itemListElement": [ {"@type":"ListItem", "position":"1", "item":{ "@id":"https://www.extraits-enrichis.fr/wp/", "name":"WordPress"} }, {"@type":"ListItem", "position":"2", "item":{ "@id":"https://www.extraits-enrichis.fr/installer-matomo-sur-wp-c-est-rapide-et-facile/", "name":"Installer Matomo sur un site WordPress (auto h\u00e9berg\u00e9) : rapide et facile"}} ] }Spécifications officielles
- Pour trouver la liste et les préconisations détaillées de Google , c’est bien entendu chez Google
https://developers.google.com/search/docs/advanced/structured-data/breadcrumb?hl=fr - Pour découvrir d’autres propriétés de données structurées qui ne sont apparemment pas prises en compte par Google
https://schema.org/BreadcrumbList
Sujets / autres résultats enrichis en relation
- Un résultat enrichi Guide / Tuto avec des données structurées HowTo pour augmenter la visibilité de votre contenu « tuto en X étapes » dans les résultats des moteurs
> Des résultats enrichis Guide / Tuto avec les données structurées HowTo - Des données structurées de type Recipe pour faire saliver sur vos recettes de cuisine dans les résultats des moteurs de recherche
> Recette de cuisine et Google : les résultats enrichis - Les données structurées de type LocalBusiness, pour transmettre des informations en lien avec une fiche d’établissement Google Maps, My Business, Local, Place, Address …
> Établissement local et données structurées - Avec les données structurées de type Logo, vous pouvez indiquer à Google quel est le logo de votre organisation.
> Votre logo dans les résultats de Google et sa fiche info - Un extrait enrichi est un résultat un peu particulier dans les moteurs de recherche. Petite explication pour les curieux 💡
> Google et les extraits de résultats enrichis
- De différentes « catégorisations » (ou taxonomies) intéressantes pour le visiteur
-

« Mon site n’apparait pas dans les moteurs de recherche » : ce qu’il faut vérifier
Pour résoudre ce « petit » problème, il s’agit dans la plupart des cas d’entrevoir quelques rouages des moteurs de recherche. Si vous n’êtes pas familier avec les termes employés, un petit glossaire en bas de page présente quelques éléments de jargon SEO.
Au sommaire :
- Problème de référencement ou d’indexation ?
- Les pistes à explorer et les solutions
- Pour continuer
- Glossaire : quelques éléments de langage SEO
Problème de référencement ou d’indexation ?
Pages mal positionnées Vs. pas indexées
Il faut bien distinguer
- les pages qui apparaissent très peu dans les résultats des moteurs de recherche parce qu’elles ne sont pas trouvées là où vous les attendez
Il y a manifestement d’autres pages considérées comme plus pertinentes par les moteurs, que cela soit juste ou pas. C’est tout le cœur de métier des référenceurs, et ce n’est pas l’objet de ce post. - les pages qui n’apparaissent pas du tout dans les résultats des moteurs de recherche
Dans ce cas, c’est souvent un paramétrage ou un bout de code qui empêche vos pages d’être affichées dans les moteurs, ou qui bloque les robots d’exploration. C’est plus rarement quelque chose de très compliqué à régler, et vous allez trouver les principales pistes à suivre en poursuivant la lecture.
Déterminer si vous avez un problème d’indexation
Si vous avez un doute, vous pouvez taper site:votre-site.fr pour vérifier que vos pages sont présentes dans le moteur, ou site:votre-site.fr inurl:adresse-de-ma-page pour une vérification plus ciblée.
Si les résultats proposés sont beaucoup moins nombreux que ce à quoi vous pouvez légitimement prétendre, ou si des résultats indiquant « Pas d’informations disponibles sur cette page » ou « La description de ce résultat n’est pas accessible à cause du fichier robots.txt de ce site. »), vous pouvez aussi trouver la solution dans les paragraphes qui suivent.
Des années que Linguee.fr et sa traduction campent en haut de la première page de Google, sur la recherche « la page a disparu »… Les pistes à explorer et les solutions
Les quelques paragraphes qui suivent donnent quelques pistes pour débloquer le référencement d’un site introuvable dans les moteurs. Bien entendu, vous pouvez lire ce que Google conseille de faire (et vous devriez). La page de Google aborde des points supplémentaires, mais elle nécessite un certain effort de documentation pour ceux qui ne sont pas familiers avec le SEO.
Explorons donc rapidement les critères les plus évidents qui empêchent l’apparition d’un site dans les pages de résultats de recherche : et en miroir ce qu’il faut faire pour que les moteurs puissent découvrir vos pages et parcourir leurs contenus.
Les robots des moteurs peuvent-ils accéder aux pages ?
Pour indexer une page dans un moteur de recherche, il faut que les robots puissent y accéder. Ça paraît évident :
- Les pages qui nécessitent une identification sont inaccessibles aux robots (identifiant / mot de passe).
S’il y a un blocage lorsqu’un internaute lambda accède à la page, il y a sans doute une raison (bonne ou mauvaise).
Seule la levée de ce blocage rendra possible l’apparition de vos pages dans les moteurs de recherche.
- La page doit être valide, le code de réponse doit être ok : heureusement les moteurs ne veulent pas nous amener sur des erreurs de navigation, des erreurs serveur, … ils cherchent à explorer et proposer des codes 200, c’est à dire des adresses valides.
Testez l’affichage de la page dans votre navigateur, et dans le doute, vérifiez donc ce code de réponse. A moins que vous ne sachiez utiliser la console de votre navigateur, aidez-vous d’outils tels que un outil tel que https://www.outiref.fr/ (onglet technique), https://www.afficheip.net/services/test-redirection.php, ou d’une extension de navigateur comme MozBar ou OnCrawl.
Même si cela semble évident, mieux vaut vérifier que la page se charge correctement dans un navigateur.
Le contenu peut-il être lu et indexé par les moteurs ?
L’accès des robots à une page est indispensable, mais il faut aussi que les robots soient « autorisés » à lire son code et à indexer son contenu.

Cas d’école, version cancre - Le fichier robots.txt est parfois paramétré de façon à bloquer des fichiers qui devraient pouvoir être « lus » par les moteurs. En effet, il faut que les robots puissent lire tous les fichiers utilisés pour l’affichage des pages du site : HTML, règles de style CSS, JavaScript, images…
Vérifiez dans le fichier robots.txt présent à la racine de votre site (votre-site.fr/robots.txt) qu’il n’y a pas de contenu (pages, images, css, js) concernés par les règles « Disallow: ».
Si le fichier robots.txt n’existe pas, créez le, c’est important pour les moteurs de recherche (même s’il est presque vide).
Les outils Google Search Console et Bing Webmaster Tools sont très utiles pour identifier ces blocages (d’autres outils gratuits sans inscription existent tel que https://en.ryte.com/free-tools/robots-txt/ et https://sitechecker.pro/fr/robots-tester/ par exemple).
Si des fichiers utiles à l’affichage de votre site, et notamment vos pages HTML, sont bloqués par le fichier robots.txt, il faut sans attendre le modifier pour donner une chance à vos pages d’être lues et référencées dans les résultats des moteurs de recherche.
Voici une version basique des lignes qui doivent y figurer :
User-agent: *
Disallow:
sitemap: https…
La ligne User-agent indique les robots concernés par ces règles : l’étoile (*) indique « tous », autant laisser tel quel, cela évite de lister les robots concernés par ces règles (de toute façon, ceux que vous voudriez interdire n’en tiendront pas compte).
La ligne Disallow indique les pages ou répertoires que vous souhaitez interdire à la lecture des robots. Attention, si vous ajoutez un slash (/) après les deux points, vous interdisez la lecture de toutes les pages du site !
La ligne sitemap est facultative, à compléter avec l’adresse de votre fichier sitemap valide s’il existe.
- La balise meta robots, paramétrée en noindex, empêche la page d’être indexée. Si elle est présente, vous pouvez trouver cette balise en explorant le code source de la page, en utilisant une extension de navigateur ou un outil tel que https://seositecheckup.com/tools/noindex-tag-test.
Voici le code source pour ne pas référencer une page dans les moteurs et qui ne doit pas apparaitre dans les pages que vous souhaitez référencer : <meta name= »robots » content= »noindex »>
Beaucoup d’outils existent, Google Search Console et Bing Webmaster Tools peuvent être très utiles.
Bien entendu, si vous trouvez cette balise robots paramétrée en noindex, il faut agir pour autoriser les moteurs de recherche à indexer vos pages. Pour cela, vous pouvez soit supprimer complètement la balise, soit changer le « noindex » en « index ».
Dans certains cas, la consigne robots noindex est transmise non pas dans une balise mais dans une entête de réponse http : c’est un peu plus compliqué à détecter et à traiter.
- Certaines technologies utilisées sur le web sont parfois compliquées à gérer pour le référencement. Comme autrefois les site en full Flash, les frameworks JS peuvent être très difficiles à référencer, en fonction de la façon dont ils ont été déployés.
Si vous souhaitez vérifier la lecture que Google et Bing font de vos pages, rendez-vous en premier lieu sur https://search.google.com/test/mobile-friendly et sur https://www.bing.com/webmaster/tools/mobile-friendliness pour un premier aperçu. Pour aller plus loin, il faudra encore aller dans la Google Search Console et les Bing Webmaster Tools.
Ces cas-là concernent généralement des sites complexes et si les solutions existent, elles nécessitent souvent des ajustements assez lourds en termes de développement.
- La balise ou directive canonical, l’existence d’un contenu identique, des problèmes de sécurité, ou une pénalité liée à votre nom de domaine peuvent aussi expliquer l’absence d’un site ou de pages dans les moteurs de recherche.
Ces cas-là concernent des problématiques non pas rares, mais moins fréquentes. N’hésitez pas à creuser la documentation de Google ou à demander de l’aide à un référenceur.
Pour continuer
Il s’agit bien d’une des bases du référencement naturel : l’indexation ou l’accès aux contenus sont fondamentaux. Les causes d’un référencement bloqué sont parfois plus difficiles à détecter et à résoudre : lancez donc des appels à l’aide, si possible à des référenceurs. Si vos pages sont présentes dans les moteurs mais pas aussi visibles que vous le souhaiteriez, il faut explorer d’autres pistes et en particulier
- la qualité de vos contenus
- la proximité de vos contenus avec les besoins des utilisateurs que vous voulez atteindre,
- la manière dont ils expriment ces besoins,
- ce qu’ils s’attendent à trouver comme réponses
- la notoriété/popularité de vos pages, comparée aux sites positionnés en haut du classement
Glossaire : quelques éléments de langage SEO
- Robots des moteurs de recherche : les robots des moteurs de recherche sont des programmes qui explorent le web de lien en lien.
- Indexation : les robots des moteurs de recherche explorent les liens qu’ils trouvent dans les pages. L’indexation, c’est le processus qui découle la découverte d’une nouvelle adresse de page web par un robot : le moteur décide d’inclure et de classer la page dans son « catalogue » de pages évaluées. Cela ne veut pas dire que la page apparaîtra dans les résultats, mais cela signifie que la page est identifiée et peut apparaître dans les résultats en fonction des recherches effectuées.
- Code de réponse : il s’agit d’une information transmise du serveur à votre navigateur, indiquant qu’une adresse est correcte (code 200), que c’est une erreur de navigation (code 404), …
- Balise meta robots : bout de code intégré dans le code d’une page pour indiquer aux moteurs de recherche s’ils doivent indexer ou pas une page. Exemple d’utilisation le plus courant : <meta name= »robots » content= »noindex »> – indique au robots de ne pas indexer la page. Cette indication peut aussi être transmise aux robots d’une autre façon, avec l’entête de réponse http de la page.
- Robots.txt : parfois mal paramétré, ce fichier permet d’indiquer aux moteurs qu’ils n’ont pas le droit de lire le contenu des adresses listées.
-
Google Tag Manager pour le référencement
Google Tag Manager et l’injection JavaScript
À l’heure où le moteur de recherche prend en charge le JavaScript dans l’évaluation des pages qu’il explore, cela m’a titillé. Pourrait-il prendre en compte, via Google Tag Manager, les balises meta robots ? Les balises title ? Les meta referrer ? Un peu de test, d’astuce et des résultats convaincants.
(suite…) -
Les résultats « enrichis » de Google
Un extrait de résultat « enrichi » est un résultat de moteur de recherche affiché avec un petit plus :
- une photo de recette
- des notations de produit (avec des étoiles)
- une liste d’événements (concerts, expos…)
- une date discrète
- un fil d’Ariane, etc.
Ils sont aussi appelés extraits enrichis (quelle coïncidence ! ) ou rich snippets. Pour avoir une idée plus précise, voici toute une rubrique sur le sujet !
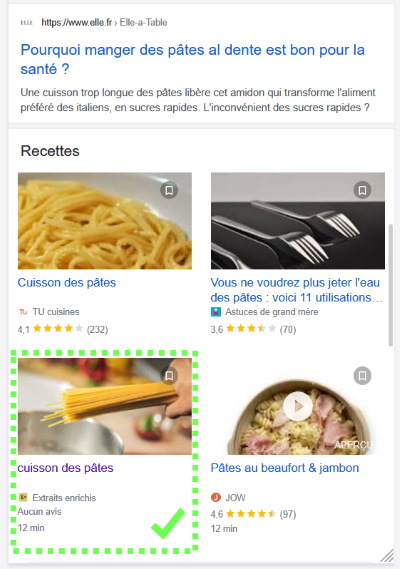
Les résultats enrichis de type recettes sont particulièrement visibles dans les pages de Google, avec un visuel, des avis, une durée de préparation, … Ces résultats sont issus d’informations spécifiques trouvées dans la page web et exploitées notamment par les moteurs de recherche.
Rien à voir donc avec les résultats financiers de Google annonçant ses dizaines de milliards de dollars de bénéfices…
(suite…)