Dernière mise à jour le 7 juillet 2025
Un extrait de résultat « enrichi » est un résultat de moteur de recherche affiché avec un petit plus :
- une photo de recette
- des notations de produit (avec des étoiles)
- une liste d’événements (concerts, expos…)
- une date discrète
- un fil d’Ariane, etc.
Ils sont aussi appelés extraits enrichis (quelle coïncidence ! ) ou rich snippets. Pour avoir une idée plus précise, voici toute une rubrique sur le sujet !
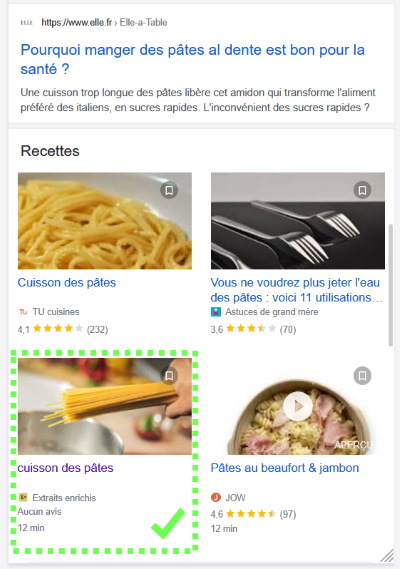
Ces résultats sont issus d’informations spécifiques trouvées dans la page web et exploitées notamment par les moteurs de recherche.
Rien à voir donc avec les résultats financiers de Google annonçant ses dizaines de milliards de dollars de bénéfices…
De quoi sont faits les résultats de recherche classiques et les résultats enrichis
Les résultats naturels des moteurs de recherche sont en très grande partie produits à partir d’informations que leurs robots récupèrent en explorant les pages web.
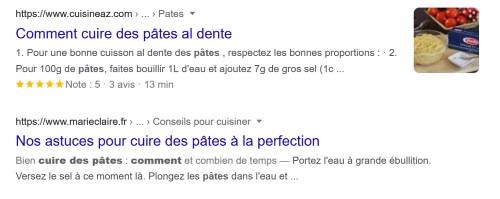
- Dans le cas d’un résultat classique, le lien-titre bleu et la description affichés dans les pages de résultats des moteurs sont souvent issus d’éléments spécifiques (balises title et meta description), renseignés quand tout va bien dans le code de chaque page. Ces éléments, constituant un résultat « classique », ne sont pas affichés directement dans les pages du site.
[Aujourd’hui, les moteurs réécrivent souvent le titre bleu ou la description quand ils ne sont pas satisfaisants par rapport aux termes de la recherche mais que le contenu de la page répond à la recherche.] - Dans le cas des extraits enrichis, qui sont des résultats classiques « améliorés », les moteurs de recherche exploitent des éléments supplémentaires : généralement des données structurées. Il s’agit d’informations transmises dans le code des pages et précisant la nature des éléments ou contenus de la page.
Les données structurées, matière principale des résultats enrichis
Les données structurées sont destinées aux robots qui explorent le web, comme d’autres éléments d’une page web (balises title et meta description, consignes d’indexation, …). Les données structurées permettent de fournir des informations spécifiés aux robots :
- Là où il y a écrit « j’adore la soupe aux choux », un moteur est censé deviner s’il s’agit du film ou du plat culinaire en s’aidant du contexte de la phrase, de la page, du site.
- Avec les données structurées, il n’y a pas plus de doute : une suite de chiffres devient à ses yeux un numéro de téléphone, un code postal ou une référence ISBN. Ou un film épique.
Les données structurées permettent donc de créer un véritable « graphe de connaissance » à travers le web (et même au-delà, puisqu’elles peuvent être déployées dans les mails par exemple).
Mais ce sont avant tout les principaux moteurs de recherche qui exploitent les données structurées. Avec toutes ces informations, ils sont capables d’associer La soupe aux choux et Shaun of the dead, ou Mozart et Shakira.
Pourquoi ça fonctionne autant ?
Paresse et consommation de l’information
Nous n’aimons pas trop avoir le choix. Souvent, une simple et unique réponse est plus appréciée qu’une liste de 10 résultats : météo, sujets historiques, données économiques et géographiques, séries, films et artistes, … on cherche souvent une info somme toute assez succinte. Et ça, Google l’a bien compris.
« Notre objectif est d’organiser les informations à l’échelle mondiale pour les rendre accessibles et utiles à tous. ».
https://about.google/
Les étoiles de notation, adossés à des recettes ou à des chaussures, incitent à cliquer sur les résultats concernés : les yeux sont attirés, l’information clairement affichée, le clic rapide. « Une note de 2,5 sur 5, au secours ! » ; « 1458 avis et une moyenne 4,5 sur 5 : chérie, j’achète ! » ; …
Instantanéité et Knowledge Graph de Google
En accumulant les informations précises et nombreuses des données structurées publiées dans les pages web, en les associant et en les liant à d’autres sources telles que Wikipedia, Google construit petit à petit une nouvelle référence appelée Knowledge Graph.
L’objectif de Google ? « Organiser les informations à l’échelle mondiale pour les rendre accessibles et utiles à tous »
(je sais, c’est écrit juste au-dessus, c’est pour voir ceux qui suivent).
Cela pose bien sûr des questions : une information lue via Google est souvent considérée à première vue comme une information exacte. Le moteur est utilisé par près de 95% des internautes. Sa responsabilité devient de plus en plus importante quand il fournit lui-même les réponses, et qu’il n’aiguille plus (ou beaucoup moins) vers un panel de réponses.
- Quand le moteur fournit des liens, nous pouvons facilement questionner les sites sur lesquels nous lisons des réponses.
- Quand le moteur fournit directement la réponse, et qu’on a l’habitude d’obtenir des résultats pertinents, fait-on encore le moindre effort d’esprit critique ?
Il faut bien le reconnaitre, le succès du moteur ne s’est pas bâti sur des résultats loufoques ou bourrés d’informations inexactes. Il a proposé des résultats suffisamment pertinents, juguler les sites de SPAM et convaincre les sites du monde entier (ou presque) de suivre ses règles.
L’évolution du Knowledge Graph semble très logique pour le moteur (intelligence artificielle, machine learning, … ). Mais celui qui en connait tant sur ce que nous cherchons, qui nous fournit des réponses directement et tend même à devancer nos questions… S’il connait les questions et les réponses à l’avance, ne risque-t-il pas de fausser son propre jeu ? De perdre l’à-propos qui a participé à son succès ?